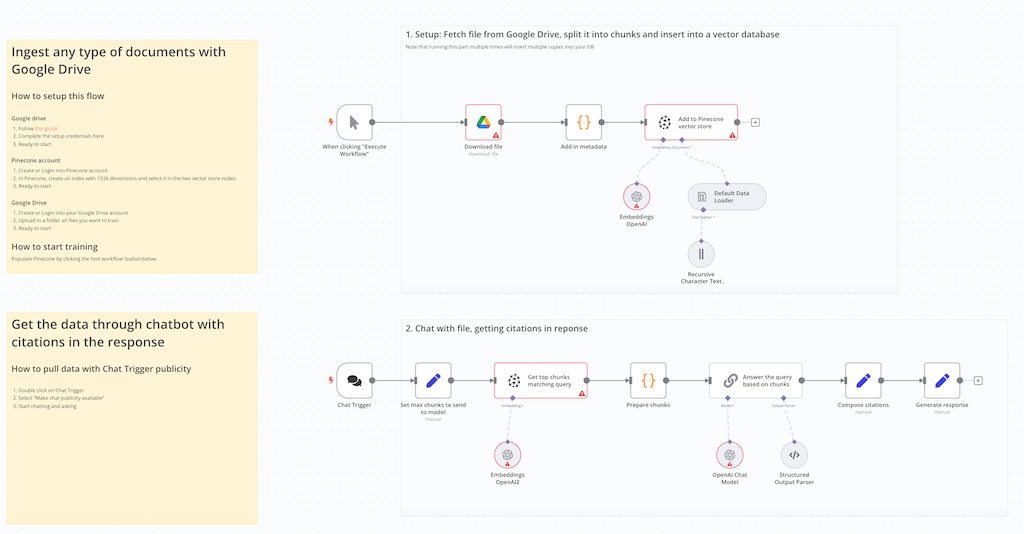
Build a RAG Chatbot with n8n: Seamless Data Integration for Accurate Responses – [Tutorial Step-by-Step]
Learn how to merge structured and unstructured data in n8n, generate embeddings with OpenAI, and store them in a vector database to power a context-aware chatbot with Retrieval Augmented Generation

![Build a RAG Chatbot with n8n: Seamless Data Integration for Accurate Responses – [Tutorial Step-by-Step]](https://images.unsplash.com/photo-1587397070638-81d3cce10435?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDN8fEtub3dsZWRnZSUyMGJhc2V8ZW58MHx8fHwxNzM2NDM3NzIyfDA&ixlib=rb-4.0.3&q=80&w=2000)
In this tutorial, you will learn how to build a Retrieval Augmented Generation (RAG) chatbot in n8n that unifies two different data sources — structured and unstructured—into a single flow, creates embeddings with OpenAI, stores them in a vector database, and finally exposes the data through a chatbot to answer user questions accurately.
What's the deal with RAG?
Retrieval Augmented Generation (RAG) combines large language models (LLMs) with external knowledge sources.
Rather than relying purely on the model’s internal parameters, the chatbot can retrieve data from a vector database populated with your own documents. This helps reduce hallucinations and provides context-aware replies.
Let's break down how you can build a RAG chatbot in n8n that seamlessly blends structured and unstructured data into a conversational powerhouse.
External Knowledge Sources
Instead of just relying on what it's been trained on, RAG allows your chatbot to pull in real-time data from your documents, databases, or any other data source you have.
Reducing Hallucinations
Ever had a chatbot make up facts? With RAG, those days are over. By grounding responses in actual data, your chatbot provides accurate, context-aware replies.
Let's build this chatbot!
1. Collect Data
First up, we need to gather our data.
Think of this like setting up your ingredients before cooking: unstructured data, structured data and semi-structured data. Introduce each one to be conscious of where are you starting and how to deal with them correctly before training your chatbot.
Unstructured Data
This could be PDFs, text files, or any document where the data isn't neatly organized. Imagine your company's policy documents or customer feedback forms.
This type of data is typically text-heavy but may also include multimedia content. Unlike structured data, unstructured data lacks a consistent format, making it more challenging to collect, process, and analyze.
However, advancements in technologies like natural language processing (NLP) and machine learning have improved the ability to extract meaningful insights from unstructured data.
- Lack of Predefined Structure: No specific format or schema, making it flexible but harder to manage.
- Variety of Formats: Can include text, images, videos, audio, and more.
- Difficult to Search and Analyze: Requires advanced tools and techniques to process and extract information.
- High Volume: Often generated in large quantities, especially from digital interactions.
Examples:
- Emails: Free-form text communications without a standardized format.
- Social Media Posts: Tweets, Facebook updates, Instagram captions, and comments.
- Multimedia Files: Images, videos, and audio recordings stored in formats like JPEG, MP4, or MP3.
- Documents: Word processing files, PDFs, and presentations that contain a mix of text, images, and other media.
- Customer Reviews and Feedback: Unstructured text data from platforms like Amazon reviews or survey responses.
- Web Pages: HTML content that includes text, images, and embedded media without a uniform structure.
Structured Data
This is your neatly organized data, like rows in a CSV or entries in a MySQL database. Think sales records or customer profiles.
Structured data refers to highly organized information that resides in fixed fields within a record or file. This type of data is easily searchable and can be efficiently stored, accessed, and analyzed using traditional data management systems like relational databases. Structured data follows a strict schema or format, ensuring consistency and facilitating straightforward querying and reporting.
- Highly Organized: Data is stored in a predefined manner, often in tables with rows and columns.
- Easily Searchable: Due to its organized nature, structured data can be quickly queried using languages like SQL.
- Consistent Format: Adheres to a specific schema, ensuring uniformity across data entries.
- Efficient Storage: Optimized for storage and retrieval in databases.
Examples:
- Relational Databases: Information stored in systems like MySQL, PostgreSQL, or Oracle databases. For instance, a customer database with tables for customers, orders, and products.
- Spreadsheets: Data organized in rows and columns, such as sales figures in an Excel sheet.
- CSV Files: Comma-Separated Values files where data is arranged in a tabular format.
- Enterprise Resource Planning (ERP) Systems: Structured data used in managing business processes like inventory, accounting, and human resources.
Semi-Structured Data (Bonus)
While not explicitly requested, it's beneficial to mention semi-structured data as it bridges the gap between structured and unstructured data.
Semi-structured data contains elements that can be organized into a hierarchy or another structure, but it does not reside in a rigid framework like structured data. It includes tags or markers that separate semantic elements and enforce hierarchies of records and fields within the data.
Examples:
- JSON (JavaScript Object Notation): Data format used for transmitting data in web applications, which includes key-value pairs.
- XML (eXtensible Markup Language): Markup language that defines rules for encoding documents in a format readable by both humans and machines.
- NoSQL Databases: Databases like MongoDB and Cassandra that store data in flexible formats, allowing for varying structures within the same database.
2. Blending data in n8n
It enables users to connect various data sources, transform data seamlessly, and orchestrate complex workflows without extensive coding knowledge. In this chapter, we'll walk through the process of unifying structured and unstructured data using n8n, setting the foundation for building intelligent chatbots and other data-driven applications.
Step 1: Initiate Your Workflow with a Start Node
Every workflow in n8n begins with a trigger that kickstarts the automation process. Depending on your specific requirements, you can choose from a variety of trigger nodes:
- Start Node: Ideal for manual or scheduled workflows. It acts as the entry point without any external trigger.
- Webhook Node: Perfect for workflows that need to respond to external HTTP requests.
- Scheduler Node: Use this if you want your workflow to run at specific intervals (e.g., daily, hourly).
Example: If you want your workflow to run every time a new file is added to a specific folder, you might use a Webhook or File Trigger node accordingly.
Step 2: Integrate data sources with data nodes
Once your workflow is initiated, the next step is to bring in data from various sources. n8n offers a plethora of nodes tailored for different data types and sources.
In this example I added Google node to pull any types of files into the workflow.
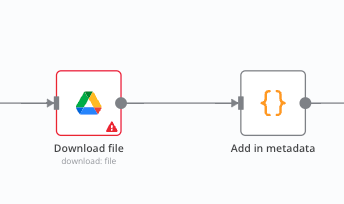
Step 3: Clean and transform your data
Raw data often requires cleaning and transformation to ensure consistency and usability. n8n provides versatile nodes to handle these tasks:
- Function Nodes: Write custom JavaScript code to manipulate data as needed. This is useful for complex transformations that aren't covered by standard nodes.Example: Extracting specific fields from a block of unstructured text or normalizing date formats across different data sources.
- Set Nodes: Modify data fields, assign new values, or rename fields without writing code.
- Merge and Split Nodes: Combine data streams from multiple sources or split data into different paths based on conditions.
CustomerID.Step 4: Merge data streams
The true power of n8n lies in its ability to seamlessly merge disparate data streams into a unified dataset. The Merge Node allows you to combine data in various ways:
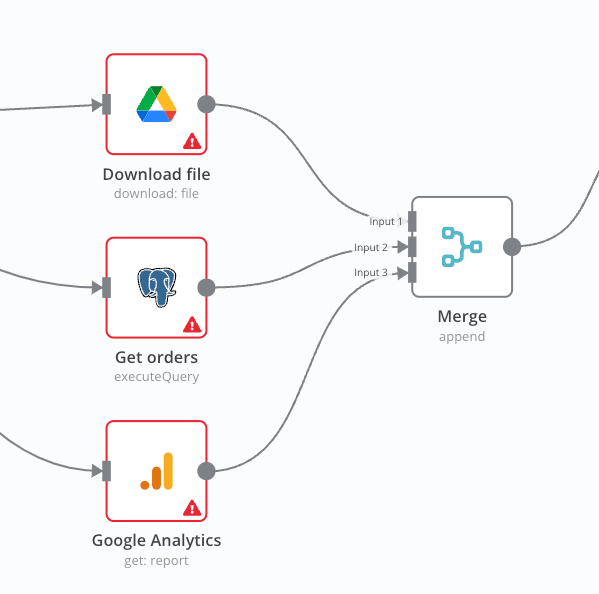
- Append Merge: Stacks data from multiple sources vertically, adding more records to the dataset.
- Merge by Fields: Combines data horizontally based on matching fields, enriching the dataset with additional information.
- Full Outer Join: Ensures that all records from both data sources are included, even if there are no matching fields.
CustomerID, allowing you to analyze how feedback correlates with sales performance.Step 5: Create embeddings with OpenAI
With your data unified, the next step is to make it chatbot-friendly by converting textual information into embeddings—numerical representations that capture the semantic meaning of the text.
This process involves leveraging OpenAI's Embeddings API and store into Pinecone Vector database:
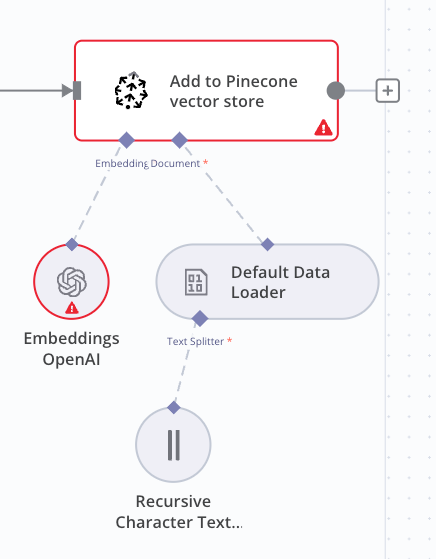
Generate Embeddings
For each piece of text in your unified dataset, send a request to the API to generate its embedding using a model like text-embedding-ada-002.
These embeddings translate your textual data into a format that machine learning models can easily interpret and analyze.
Store Embeddings
These vectors will later enable efficient similarity searches and context-aware responses in your chatbot.
Step 6: Querying
When a user poses a question, generate an embedding for the query and perform a similarity search against the stored vectors.
It retrieves the most relevant documents or data points that closely match the user's intent, enabling the chatbot to provide accurate and contextually appropriate responses.
From data unification to chatbot interaction
By meticulously unifying your structured and unstructured data in n8n, transforming it into embeddings, and storing it in a vector database, you establish a robust foundation for building intelligent chatbots.
This streamlined process ensures that your chatbot can access, understand, and utilize your data effectively, leading to more meaningful and accurate interactions with users.
- Start with Data: Gather from both structured and unstructured sources.
- Merge and Normalize: Inside n8n, blend these data streams into one coherent flow.
- Embeddings: Use OpenAI to create embeddings, making your data chatbot-ready.
- Store: Populate your vector database with these embeddings.
- Chatbot phase: When a user asks a question, your chatbot retrieves the most relevant data, combines it with the query, and crafts a response.
And there you have it! You've just built a RAG chatbot that not only talks but also thinks like a pro.
This isn't just about answering questions; it's about providing value, reducing errors, and enhancing customer experience with every interaction. 🚀
Start building your RAG chatbot today and watch your customer interactions transform!
If you have any questions or need a bit more guidance, feel free to drop me a line. Let's make your chatbot the smartest in town! 😎
Download this RAG
Click the link below and subscribe to the newsletter to download it.