RAG for B2B SaaS: How to Use Retrieval-Augmented Generation Across the Customer Lifecycle
An N8N example RAG is downloadable for free in this article


RAG (Retrieval-Augmented Generation) for B2B SaaS is an AI architecture that connects a large language model to your proprietary business data — product documentation, CRM records, support history, pricing, contracts — so every AI-generated output is grounded in your actual, current knowledge base rather than generic training data. Applied across the customer lifecycle, it transforms how SaaS teams handle sales enablement, onboarding, customer success, support, and expansion revenue — replacing static, manually maintained content with dynamic, context-aware intelligence that updates as your product and customers evolve.
In 2026, RAG is no longer an engineering experiment. It is the operating system for SaaS teams that want to shorten sales cycles, cut onboarding time-to-value, reduce churn, and unlock expansion revenue from existing accounts — without proportionally scaling headcount.
Why This Matters Now (Strategic Context)
B2B SaaS economics have fundamentally shifted. Approximately 40% of SaaS revenue now comes from renewals and expansion — not new logo acquisition — according to Benchmarkit research cited by Gainsight. That means the teams responsible for retention and growth (Customer Success, Support, Sales) are now the primary revenue engines, and they are the exact teams drowning in tribal knowledge, outdated documentation, and manual content production.
RAG solves the structural inefficiency at the core of every SaaS lifecycle team: the gap between what your organization knows and what individual team members can access and act on in real time. A CS rep preparing for a renewal call, a sales rep answering an RFP at 11 PM, an onboarding specialist handling a complex integration question — all of these moments are won or lost based on information retrieval speed and accuracy. RAG makes every team member as knowledgeable as your best-performing expert, at query time, every time.
The market reflects this urgency. The global RAG market reached $1.35B in 2024 and is forecast to grow at a 40.3% CAGR through 2032, reaching $19.16B — with B2B SaaS as one of the fastest-adopting verticals, driven by the density and complexity of proprietary knowledge assets that SaaS organizations accumulate.
Key Data and Market Reality
- 40% of SaaS revenue comes from renewals and expansion — Customer Success teams running RAG-powered intelligence are directly positioned to protect and grow this revenue (Benchmarkit / Gainsight, 2026)
- 34% churn reduction and time-to-value cut from 22 days to 8 days reported by a SaaS company after deploying AI-automated onboarding guidance; activation rates jumped from 62% to 89%
- 70% reduction in proposal creation time (from 20 hours to 6 hours per RFP) and a 15% RFP win rate increase (42% → 57%) achieved by a technology consulting firm using a RAG-powered sales enablement platform (Remaker Digital, January 2026)
- 23% of SaaS churn is directly attributable to poor onboarding experiences; customers with strong onboarding show 30% higher lifetime value (EverAfter, 2025)
- RAG-based customer support applications account for ~35% of total RAG market revenue in 2024, with 24/7 self-service at scale as the primary driver (Navis Research, 2025)
- More than 70% of B2B SaaS providers are expected to incorporate AI agents or RAG into their platforms by end of 2026 (GoSaasili, 2025)
What Is RAG and Why Does It Matter for SaaS Teams?
RAG combines two components: a retrieval layer (vector database + semantic search) and a generation layer (LLM).
When a team member or customer submits a query, the system first retrieves the most relevant chunks from your indexed knowledge base — product docs, call transcripts, CRM notes, contracts, support tickets — then passes that live context to the LLM, which synthesizes a precise, grounded response.
The critical distinction from a standard LLM or AI chatbot: the model does not answer from its training memory. It answers from your proprietary data, at query time.
This eliminates hallucinations about your specific product, pricing, or customers — a failure mode that is commercially catastrophic in B2B contexts, where a wrong answer on a compliance question or a misquoted SLA can kill a deal or trigger a legal escalation.
The RAG Pipeline Applied to SaaS
- Indexing — Product documentation, release notes, CRM account data, support ticket history, RFP response libraries, and contract templates are chunked, embedded, and stored in a vector database
- Retrieval — At query time, the question is semantically matched against the index; the top-K most relevant chunks are retrieved with metadata (source, date, account)
- Generation — The LLM receives the retrieved context + query and generates a grounded, cited, natural language response — with a traceable source for every claim
How Can SaaS Teams Use RAG?
5 Lifecycle Stages
Stage 1: Pre-Sales and Sales Enablement
Sales cycles in B2B SaaS are bottlenecked by information retrieval: reps spend hours manually searching case studies for the right industry example, looking up product specifications to answer a technical question, or assembling RFP responses from scattered documents. RAG eliminates this friction.
A RAG-powered sales enablement system indexes your entire content library — case studies, battle cards, product specs, security questionnaires, pricing tables, contract templates — and allows reps to retrieve precise, synthesized answers in seconds. Instead of building a proposal manually over 20 hours, a rep prompts the system: "Generate a proposal for a logistics company focused on our real-time tracking features. Include the Global Transport case study and enterprise pricing." The system retrieves the relevant components and assembles a coherent first draft in minutes.
Production results: A technology consulting firm deploying RAG for sales enablement cut proposal creation time by 70% (20 hours → 6 hours), increased RFP win rate from 42% to 57%, and achieved 95% sales team adoption — generating an estimated $400K in annual value with a 3-month payback period.
RAG use cases in pre-sales:
- Automated RFP and proposal first drafts grounded in past winning proposals
- Real-time objection handling: retrieve the exact competitive differentiator or customer evidence at the moment it's needed
- Instant product specification lookup for technical sales calls
- Personalized battle cards per competitor, per deal vertical, per ICP segment
Stage 2: Customer Onboarding
Poor onboarding is one of the highest-leverage churn drivers in SaaS: 23% of churn traces directly to inadequate onboarding experiences, and customers who complete onboarding within 7 days show 3× higher long-term retention rates than those who take 14+ days. RAG addresses the two core onboarding failure modes: information overload and delayed time-to-value.
A RAG-powered onboarding assistant gives new users a conversational interface to your entire product knowledge base — integration guides, API documentation, configuration walkthroughs, role-specific use case libraries — so they can ask questions in natural language instead of filing support tickets or waiting for a CSM. The system retrieves the exact relevant documentation chunk and delivers it in context, without the user navigating a 400-page wiki.
Production results: A SaaS company deploying AI-automated onboarding guidance reduced time-to-value from 22 days to 8 days, increased activation rates from 62% to 89%, reduced onboarding-related support tickets by 47%, and achieved a 34% overall churn reduction — with startups showing a 41% improvement.
RAG use cases in onboarding:
- Role-based onboarding assistants: the answer a developer needs is different from what a marketing manager needs — RAG personalizes by retrieved context, not just user segment
- Integration and API support: ground answers in your actual technical documentation, not approximations
- Progress-aware guidance: RAG connected to product usage data surfaces the next relevant step based on what the user has and hasn't completed
- Automated onboarding health scoring: retrieve signals from behavioral data and CRM to flag at-risk new accounts before the 30-day drop-off window
Stage 3: Customer Support
Support is where RAG produces the most immediately measurable ROI in SaaS — because every support ticket has a known cost, a response time SLA, and a customer satisfaction score. RAG-powered support systems handle complex, multi-context questions by retrieving from product documentation, known issue logs, previous ticket resolutions, account history, and policy documents simultaneously, generating grounded, accurate answers in seconds.
The difference from a FAQ bot: a RAG system handles the novel combination of context — "I'm on Enterprise plan, trying to connect via SSO to Okta, getting error 403 on our EU instance, which was fine yesterday." A bot returns keyword-matched articles. A RAG system retrieves the SSO troubleshooting guide + the EU instance change log from yesterday + the Enterprise plan permission model + a similar resolved ticket — and synthesizes a specific, actionable response.
Production results: RAG-enabled support deployments consistently handle 40–50% more tickets without additional headcount, while reporting +63% improvement in customer satisfaction scores. RAG-based chatbots account for approximately 35% of total RAG market revenue, making support the largest single use case in commercial deployment.
RAG use cases in customer support:
- Tier-1 deflection: handle common technical questions with documentation-grounded answers, 24/7
- Agent assist: retrieve relevant context for human agents handling escalations — reducing handle time without replacing expertise
- Escalation intelligence: RAG-powered triage routes tickets based on semantic understanding of the issue, not keyword tags
- Policy-grounded responses: warranty, SLA, refund, and compliance questions answered from the actual policy document, not the model's approximation
Stage 4: Customer Success and Retention
Customer Success teams operating without RAG spend disproportionate time on information retrieval — finding the right case study to share in a QBR, locating a specific integration guide for a power user, manually synthesizing account health signals before a renewal call. RAG restores that time to relationship work.
A RAG-powered CS platform connects to your CRM, product usage data, support ticket history, NPS scores, and contract terms — giving CSMs a real-time, synthesized view of every account's health before every interaction. When a CSM asks "What are the key risk signals for this account ahead of renewal?", the system retrieves recent usage drops, open support tickets, sentiment from last two NPS responses, and contract end date — and generates an account brief in seconds.
RAG use cases in customer success:
- Pre-call account briefs: synthesize CRM data, usage metrics, support history, and NPS into a 3-paragraph briefing before every QBR or renewal call
- Proactive churn signals: retrieve behavioral patterns from product usage data that correlate with churn risk; surface them before the CSM's next touchpoint
- Knowledge sharing at scale: CSMs can query the full institutional knowledge base for answers to edge cases — eliminating the dependency on the one senior CSM who knows everything
- Personalized success plans: generate account-specific success milestones grounded in similar customer profiles and outcomes
Stage 5: Upsell, Cross-Sell, and Expansion Revenue
Expansion revenue is structurally underutilized in most SaaS companies because identifying the right upsell moment — and having the right context to execute it — requires synthesizing signals from usage data, product roadmap fit, contract terms, and industry trends simultaneously. This is exactly what RAG does well.
A RAG system can connect product usage telemetry with account CRM data and your product catalog to surface expansion opportunities: "Account X has hit their API call limit 3 times in the last 30 days, is on the Growth plan, and their contract renews in 45 days. The Enterprise plan removes the API limit and adds SSO — here is a one-paragraph expansion pitch tailored to their use case." This gives CSMs and Account Executives precise, timely, evidence-based reasons to initiate the expansion conversation.
RAG use cases in expansion:
- Usage-triggered upsell triggers: retrieve telemetry signals that indicate plan ceiling friction and generate personalized upgrade propositions
- Cross-sell intelligence: retrieve product usage patterns across similar accounts to identify high-probability cross-sell adjacencies
- Renewal preparation: generate renewal risk assessments and expansion talking points grounded in the full account history
- Executive business reviews: synthesize 12 months of account data, product adoption, and business outcomes into a boardroom-ready narrative in minutes
RAG vs. Fine-Tuning vs. Static Knowledge Base: The SaaS Decision Framework
| Dimension | Static Knowledge Base / FAQ | Fine-Tuning | RAG |
|---|---|---|---|
| Data freshness | Manual updates only | Frozen at training time | Real-time — synced with live data |
| Product change handling | Update lag of days/weeks | Requires full retraining | Update knowledge base in minutes |
| Personalization depth | Generic — no account context | Behavioral patterns only | Individual account, query-time context |
| Hallucination risk | None (exact content) | High on proprietary specifics | Low — grounded in retrieved documents |
| Setup cost | Low | High (compute + labeling) | Low-medium (indexing + embedding pipeline) |
| Maintenance overhead | High (manual curation) | Very high (retraining cycles) | Low-medium (automated ingestion pipelines) |
| CS / Sales team adoption | Low — requires navigation skills | Invisible (baked into model) | High — natural language interface, cited answers |
| Compliance & auditability | Full (static content) | Low (black-box weights) | High — every answer traceable to source document |
| Scalability across lifecycle stages | Limited — one system per use case | Limited — one model per domain | High — single retrieval layer serves all teams |
| Best SaaS fit | Simple tier-1 FAQ deflection | Tone/brand voice adaptation only | Complex queries, live data, multi-stage lifecycle |
The hard truth: A fine-tuned model trained on last quarter's product documentation will hallucinate features that were changed in the last release. In B2B SaaS, where products ship weekly, fine-tuning without RAG is a liability, not an asset.
Trade-offs and Limitations
| Approach | When It Works | When It Fails | Real Cost / Risk |
|---|---|---|---|
| Static knowledge base | Simple FAQ, tier-1 deflection, small stable product | Product changes frequently; queries are complex or contextual | Documentation debt compounds — stale answers accelerate churn |
| Fine-tuning only | Brand tone, writing style, domain vocabulary adaptation | Dynamic data (pricing, product, customer context changes constantly) | Expensive retraining cycles; outdated specifics within weeks of a release |
| RAG only | Live data grounding, multi-context retrieval, cross-lifecycle use | Poor source quality; unstructured or inconsistent documentation | Garbage in, garbage out — hallucinations decrease but don't disappear with dirty data |
| RAG + Fine-tuning (Recommended) | Production-grade SaaS AI: accurate AND on-brand, across all lifecycle stages | Overkill for very simple, low-stakes use cases | Higher initial architecture investment; requires data governance discipline |
The hard truth: The SaaS teams that fail at RAG implementation don't fail because of the model — they fail because their product documentation is fragmented, their CRM data is incomplete, and no one owns the knowledge base as a product. RAG amplifies your knowledge quality; it does not substitute for it.
Real-World Applied Scenario
A mid-market B2B SaaS company (project management software, ~600 enterprise accounts, 45-person CS and Support team) was experiencing annual churn of 14% — above the 10% industry benchmark — with time-to-value averaging 19 days for new accounts and CS managers spending 40% of their week on information retrieval rather than customer interaction.
The team deployed RAG in three phases over 90 days. Phase 1 indexed product documentation, release notes, and 18 months of resolved support tickets into a vector database (Weaviate), powering an internal CS assistant. Phase 2 connected the CRM (HubSpot) and product usage telemetry to the same retrieval layer, enabling account health briefs on demand. Phase 3 built a customer-facing onboarding assistant embedded in the product UI.
Outcomes at 6 months: Time-to-value fell from 19 days to 9 days. Onboarding-related support tickets fell 38%. Annual churn dropped from 14% to 9.2%. CSM capacity — freed from information retrieval — was redirected to expansion conversations, contributing to a 22% increase in net revenue retention within two quarters. The CS team size remained unchanged.
The decision that drove the outcome was knowledge base architecture before deployment: 6 weeks of documentation consolidation, metadata tagging, and CRM data cleaning before a single embedding was written. The RAG system performed at production quality from day one because the retrieval layer had clean, structured, current data to work from.
Key insight:
"RAG does not make your CS team smarter. It makes their institutional knowledge universally accessible — so every team member performs like your best."
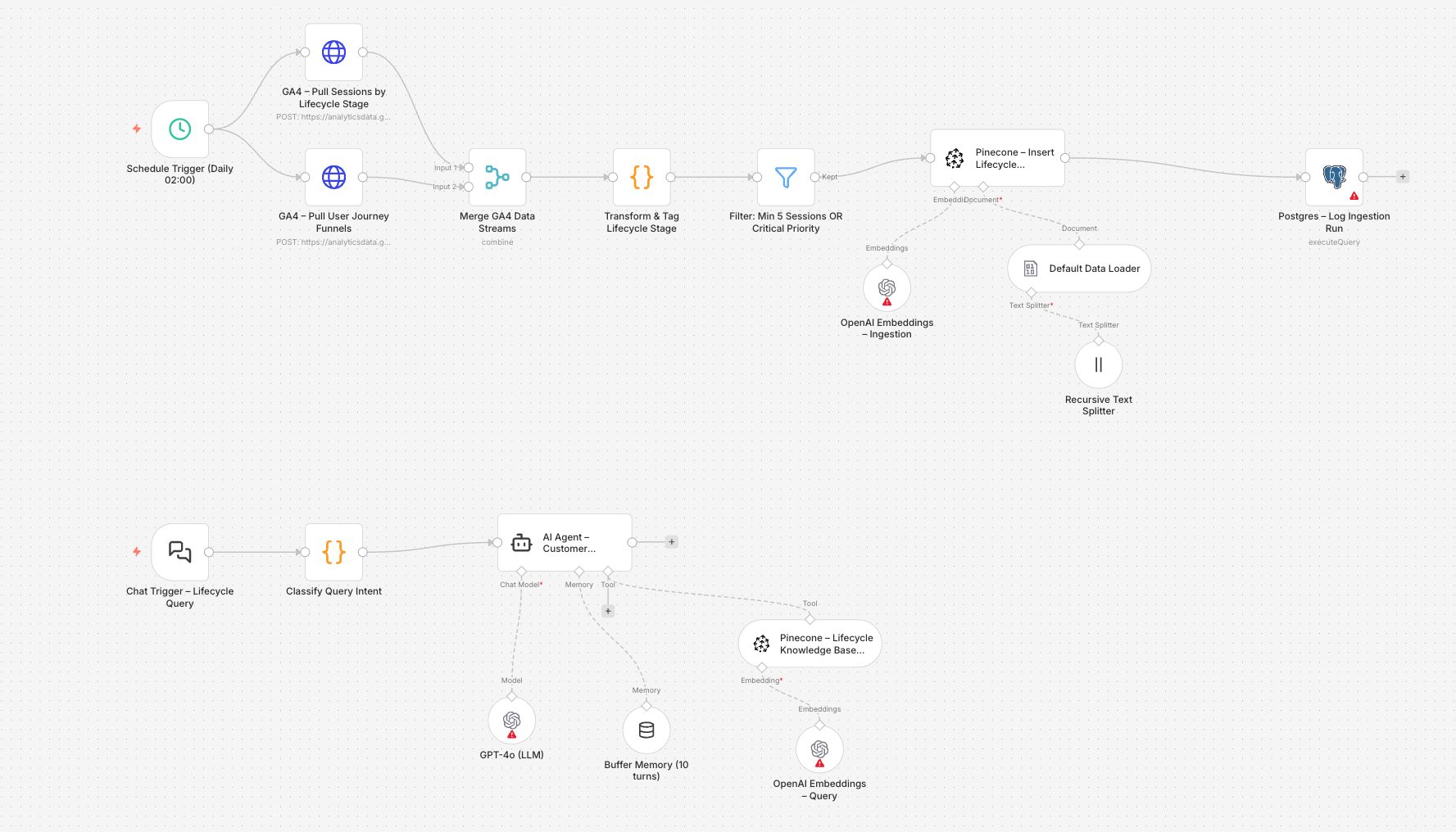
Here an example of a RAG for B2B SaaS to Analyze from GA4 and save in a Vector DB
The file contains 25 nodes across 3 fully wired sub-workflows, directly mapped to the lifecycle stages from this article.
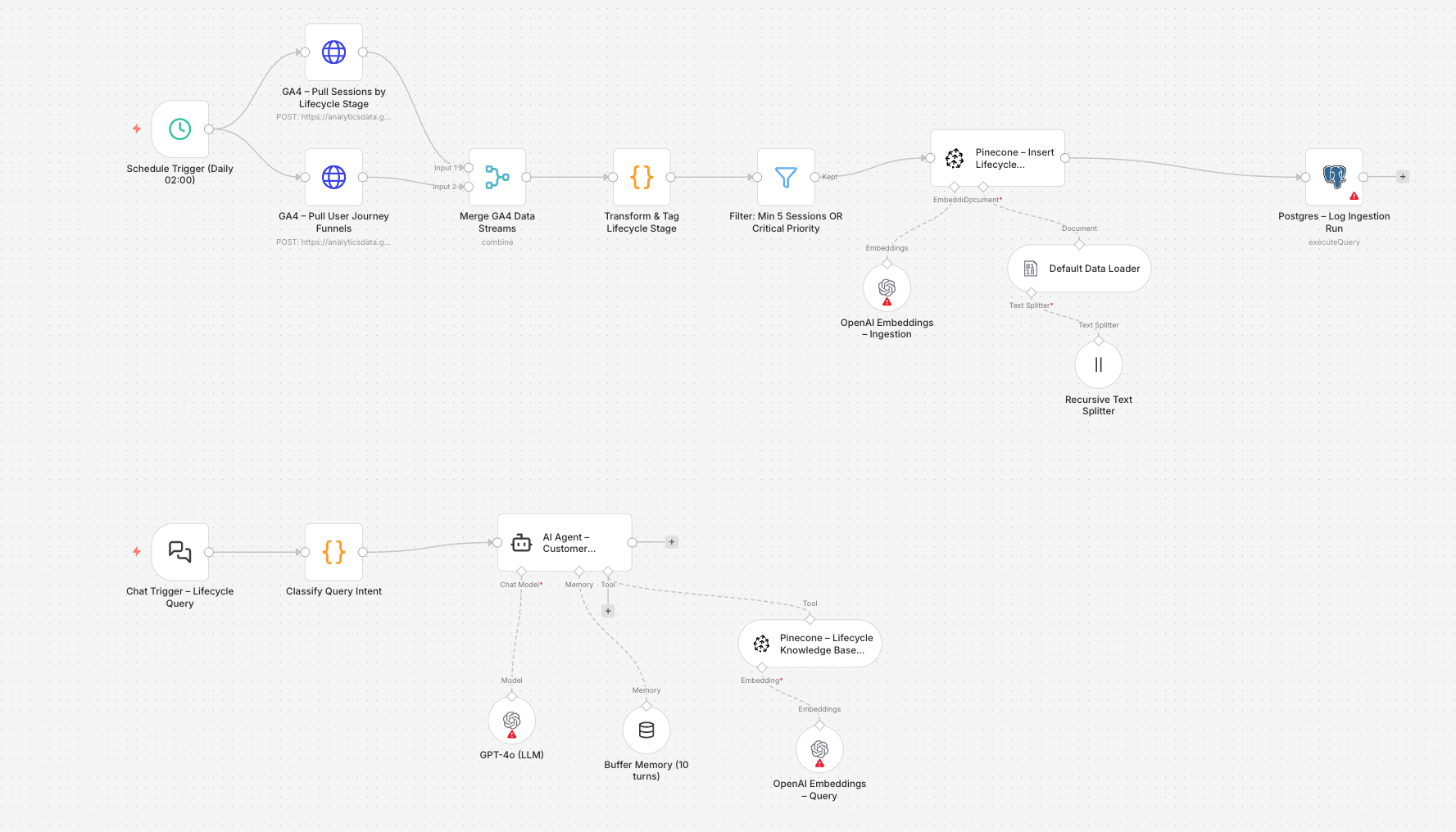
Workflow 1 — Daily GA4 Ingestion (runs at 02:00)
This pipeline pulls data from 3 parallel GA4 API calls, transforms it, and stores it in Pinecone as searchable vector embeddings.
| Node | Purpose |
|---|---|
GA4 – Pull Sessions by Lifecycle Stage | GA4 Data API v1beta runReport — pulls 30-day session data filtered by 11 lifecycle events (trial_start, demo_request, expansion_event, etc.) with 8 metrics |
GA4 – Pull User Journey Funnels | GA4 runFunnelReport — 7-step funnel from Awareness → Expansion with channel breakdown |
GA4 – Pull Churn Risk Signals | Targets accounts with days_since_onboarding > 7 AND sessions < 3 in last 14 days |
Transform & Tag Lifecycle Stage | JS code node that maps each event to a lifecycle stage, computes a 0–100 engagement score, classifies churn_risk (high/medium/low), and builds a structured text_content block for embedding |
Filter: Min 5 Sessions OR Critical Priority | Removes noise — only embeds meaningful signals |
Default Data Loader → Recursive Text Splitter → OpenAI Embeddings → Pinecone Insert | Standard N8N LangChain RAG ingestion chain — chunks at 500 tokens with 80-token overlap, embeds with text-embedding-3-small, stores under namespace saas_customer_lifecycle |
Postgres – Log Ingestion Run | Writes each pipeline run to an audit table |
Workflow 2 — RAG Chat Agent (query-on-demand)
A chat-triggered agent that classifies intent before querying Pinecone — so retrieval is always scoped to the right lifecycle context.
| Node | Purpose |
|---|---|
Classify Query Intent | JS code node maps natural language queries to one of 6 intents: churn_analysis, onboarding_health, expansion_intelligence, pre_sales, support_analysis, account_brief — and injects a tailored system_prompt_hint |
Pinecone – Lifecycle Knowledge Base Tool | Configured as an AI Tool for the agent (not a direct retriever) — returns top-8 chunks with full metadata, filtered by priority |
AI Agent – Customer Lifecycle Analyst | GPT-4o agent with a structured response format: Stage → Key Signal → Insight → Recommended Action → Critical Accounts |
Buffer Memory (10 turns) | Preserves conversation context across follow-up questions in the same session |
You can add a proactive Daily Churn Alert (e.g. 08:00 Mon–Fri)
Queries Pinecone directly for churn_risk=high + lifecycle_stage=retention, passes the results to GPT-4o for a CS-team brief, and posts to Slack #cs-alerts — no human trigger required.
Setup Checklist (embedded in the JSON)
The file includes a __setup_guide object with everything needed to go live:
- Pinecone index —
saas-lifecycle-rag, 1536 dimensions, cosine metric - Postgres table —
CREATE TABLE rag_ingestion_logSQL included - GA4 custom dimensions — 5 user-scoped and event-scoped dimensions to register in GA4 Admin (
account_id,plan_type,days_since_onboarding,lifecycle_stage,last_feature_used) - N8N variables —
GA4_PROPERTY_IDandPINECONE_INDEX - Credentials —
googleAnalyticsOAuth2Api,pineconeApi,openAiApi,postgres,slackApi - GA4 events — 12 product events that must be tracked server-side before the ingestion pipeline produces meaningful data
Key architectural decision: TheTransform & Tag Lifecycle Stagecode node is where all the intelligence lives — it converts raw GA4 dimension/metric rows into semantically richtext_contentblocks that embed cleanly. The quality of what gets stored in Pinecone is determined entirely by the quality of the GA4 event tracking upstream. Instrument your product events first; deploy the pipeline second.
👉 Download it for free here (you'll find all RAG for n8n of my articles)
FAQ
What is RAG for B2B SaaS in plain language?
RAG is an AI system that retrieves relevant information from your business's own data — product docs, CRM records, support history, contracts — and uses it to generate accurate, personalized responses in natural language. Instead of a chatbot that approximates answers from generic training data, RAG grounds every output in your actual, current knowledge base. Think of it as giving your AI a live, searchable connection to your company's institutional memory before it speaks.
How does RAG differ from a standard AI chatbot or knowledge base search?
A standard chatbot answers from training data — it can hallucinate product details, quote outdated pricing, or miss account-specific context entirely. A knowledge base search returns a list of documents for the user to read. RAG does both: it retrieves the most relevant documents semantically, then synthesizes a precise, conversational answer grounded in those exact sources — with full traceability back to the source chunk. For B2B SaaS, where a wrong answer on a compliance or pricing question can damage a deal or escalate a legal risk, that grounding is not optional.
What data does a SaaS company need to implement RAG?
At minimum: product documentation, release notes, and support ticket history. The richer the knowledge base — CRM account data, usage telemetry, contract terms, NPS feedback, onboarding completion data — the more personalized and lifecycle-relevant the outputs. Data quality matters more than volume: a clean, well-structured documentation set of 500 pages outperforms a fragmented 5,000-page wiki. Start with the highest-signal, most-used data sources; expand incrementally as the system proves value.
What is the ROI timeline for RAG in a B2B SaaS context?
The fastest ROI path is sales enablement (RFP automation) — measurable in 30–60 days, with proposal time reductions of 50–70% and win rate improvements of 10–15% reported in production. Support deflection is the second-fastest — ticket volume reductions are visible within the first billing cycle. Churn impact from RAG-improved onboarding and CS requires 90–180 days to measure reliably against a retention baseline. A 3-month payback period is achievable in sales enablement; plan for 6–9 months on retention-driven ROI.
What is the difference between RAG and fine-tuning for SaaS?
Fine-tuning adjusts a model's weights by training it on your data — the knowledge is baked in and cannot be updated without retraining. RAG keeps the model weights unchanged and retrieves current data at query time. For SaaS companies with weekly product releases, changing pricing, and evolving customer contexts, fine-tuning alone means your AI is perpetually out of date. RAG is the right primary strategy; fine-tuning is reserved for tone, brand voice, and domain vocabulary adaptation. The production-grade combination is RAG with lightweight fine-tuning — accuracy grounded in live data, delivery shaped by brand voice.
How does RAG reduce SaaS churn specifically?
RAG reduces churn through three mechanisms: faster time-to-value in onboarding (users who reach their activation moment within 7 days retain at 3× the rate of slower starters), proactive risk signal detection (connecting usage telemetry to CRM data via RAG enables CSMs to identify and address risk before renewal conversations), and support quality improvement (grounded, accurate answers to complex technical questions reduce frustration-driven churn). In aggregate, companies deploying RAG across the customer lifecycle report churn reductions of 22–36% within 6 months.
Can a mid-market SaaS company implement RAG without a large AI engineering team?
Yes. The tooling has matured significantly: managed vector databases (Pinecone, Weaviate Cloud, Supabase pgvector), LLM APIs (OpenAI, Anthropic, Azure OpenAI), and orchestration frameworks (LangChain, LlamaIndex, CrewAI) reduce implementation complexity to a manageable engineering sprint. A focused team of 2–3 engineers can deploy a production-grade RAG system in 6–12 weeks, provided the knowledge base is pre-structured. The 60-day window is dominated by data preparation, not model configuration — plan accordingly.