How to Build a Propensity-to-Buy Model Without a Data Science Team (SaaS & B2B E-commerce)

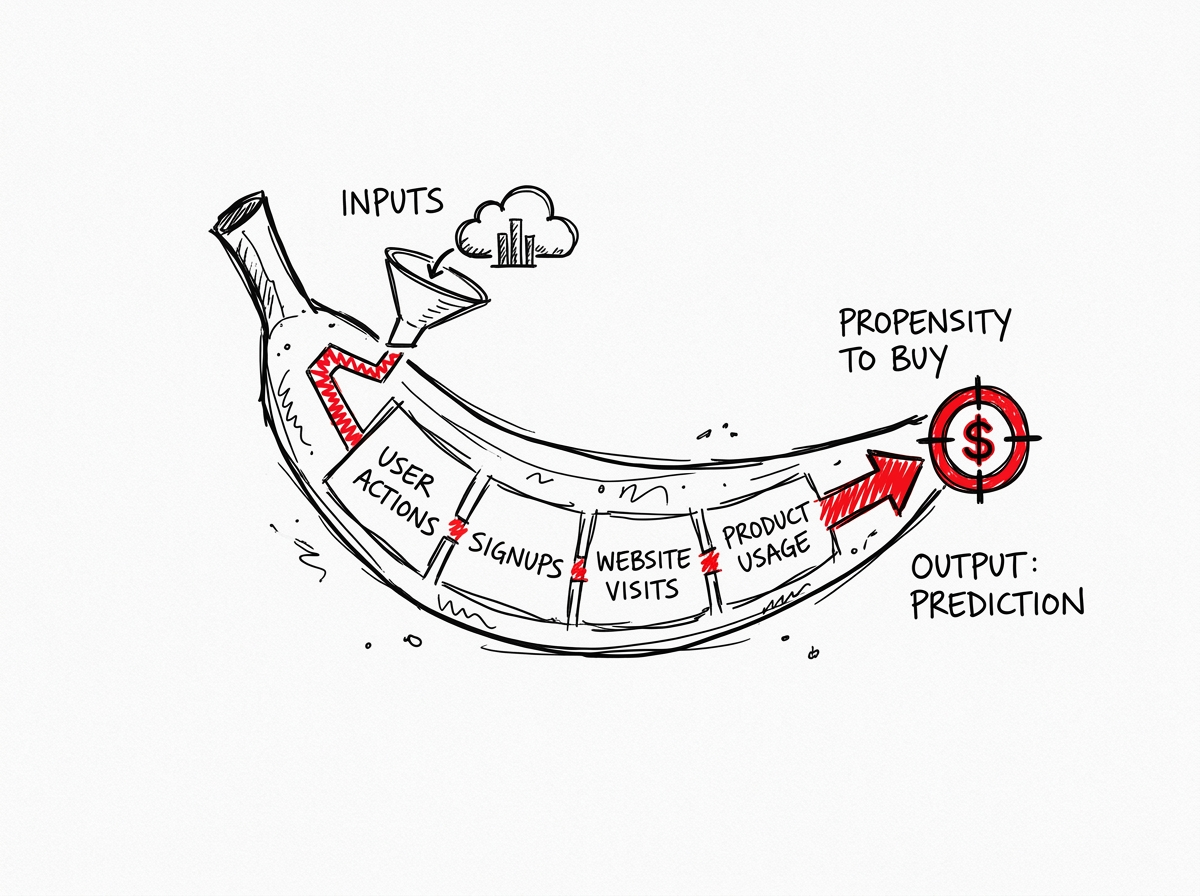
A propensity-to-buy model predicts which prospects are most likely to purchase by analyzing behavioral, firmographic, and engagement signals — and in 2026, no-code ML platforms and CRM-native tools make it possible to build one without hiring a single data scientist. SaaS and B2B e-commerce teams that deploy even a basic propensity model see 35–60% higher conversion rates on targeted segments and 20–35% lower customer acquisition costs.

Why This Matters Now (Strategic Context)
70% of high-growth B2B companies have already adopted predictive lead scoring as a core sales strategy, and the gap between adopters and laggards is widening every quarter.
Traditional lead scoring assigns static points to actions — +10 for a webinar, +5 for an email open — based on a marketer's intuition. It is a checklist. A propensity model is a compass: it uses algorithms to learn which signals actually predict closed deals, then dynamically re-weights them as buyer behavior shifts.
The urgency is compounding. In 2025, 89% of B2B buyers began using AI tools like ChatGPT during their purchase process, meaning the window between "researching" and "decision made" is shrinking. Teams that can identify high-intent accounts in real time — not next quarter — capture disproportionate pipeline. Meanwhile, AI-referred visitors convert at 17.6–24.3% compared to 1.8% for traditional organic traffic, proving that precision targeting delivers dramatically better unit economics.
Key Market Insights
Why this article makes sense today to talk about
- 70% of high-growth B2B companies use predictive lead scoring; they report up to 60% more sales-qualified leads and 30% higher campaign ROI (2025)
- Propensity-targeted segments see conversion rate improvements of 35–60% and acquisition cost reductions of 20–35%
- A D2C e-commerce company boosted sales by $1M in a single quarter after deploying a propensity-to-buy model integrated with HubSpot and Google Ads
- A billion-dollar software company using Analyzr's no-code platform identified "A-grade" accounts converting at 5× the baseline rate
- A telecom provider increased sales by 57.97% using real-time propensity-to-buy scores for call routing
- E-commerce brands report 40% higher conversion rates and 47% more revenue from propensity-targeted campaigns
How It Works: The 5-Step Process
(No Data Scientists Required)
Building a propensity model follows the same five steps whether done in a spreadsheet, a no-code ML platform, or an enterprise CRM. The difference is automation and sophistication.
Step 1 — Define the Outcome and Assemble the Dataset
Start by defining exactly what you want to predict: will this account close within 90 days? Will this lead request a demo? The outcome must be binary (yes/no) and tied to a specific time window.
Export historical data from your CRM. A minimum of 1,000–2,000 records is recommended, though more is better. Combine the outcome variable (did they convert?) with every available attribute: firmographics, behavioral signals, engagement data, and product usage metrics.
Step 2 — Select and Weight Your Signals
Signals typically fall into five buckets for B2B SaaS and e-commerce:
- Firmographic: Company size, revenue, industry, location, funding stage, growth rate
- Behavioral: Pricing page visits, case study downloads, demo requests, repeat website visits
- Engagement: Email open rates, webinar attendance, content interactions, social engagement
- Technographic: Current tech stack, integrations used, platform maturity
- Intent: Third-party intent data, competitor research signals, job postings related to your category
Recency and frequency matter. An account that visited the pricing page three times this week signals differently than one that downloaded a whitepaper six months ago. Pattern combinations are what ML excels at: a prospect who views pricing, reads case studies, engages with an ROI calculator, and visits during business hours is a fundamentally different signal than any of those actions alone.
Step 3 — Choose Your Algorithm
For teams without data science resources, start simple. Logistic regression is fast, explainable, and performs well when the dataset is clean and the use case is narrow. Random Forest is the next step up — robust, accurate, and handles messy data better than logistic regression. XGBoost and Gradient Boosted Trees deliver top accuracy on complex tabular data but require more tuning.

Step 4 — Train, Validate, and Interpret
Split your data into training (70–80%) and testing (20–30%) sets. If your positive outcome is rare (e.g., only 3–15% of leads convert), use SMOTE pre-processing to rebalance the training data.
Key metrics to evaluate your model:
- AUC (Area Under Curve): 1.0 = perfect, 0.5 = random. Target > 0.7 for a useful model
- Precision: How reliable are your "will buy" predictions?
- Recall: How many actual buyers does your model catch?
- F1 Score: Harmonic mean of precision and recall — the best single metric for imbalanced datasets
Review the feature importance chart to understand which signals drive predictions. If pricing page visits and company size dominate, that validates commercial intuition. If surprising signals appear, investigate before acting.
Step 5 — Deploy and Activate
Push scores back into your CRM. Create action tiers:
- High propensity (score 80–100) → Direct sales outreach with personalized demo invite
- Medium propensity (score 40–79) → Nurture with targeted email sequences and retargeting
- Low propensity (score 0–39) → Automated drip campaigns or deprioritize
Set up Slack alerts or CRM workflow triggers when accounts cross thresholds. Retrain the model quarterly or whenever you notice performance degradation (model drift).
Trade-offs and Limitations
A propensity model is not a magic wand — it is a decision support system that guides humans toward smarter action, not a replacement for sales judgment.
FAQ
Can I build a useful propensity model with fewer than 1,000 records?
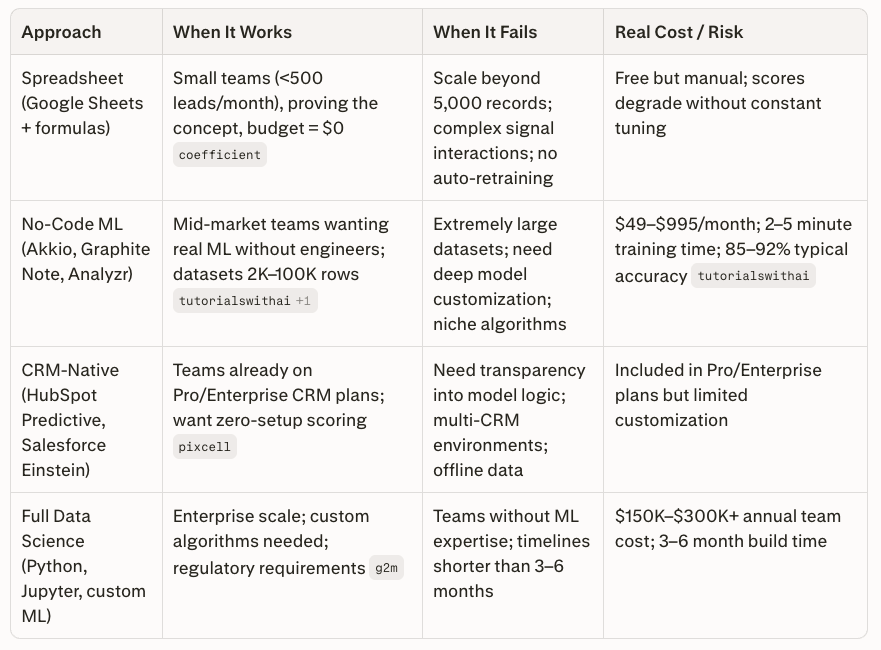
Technically yes, but model reliability drops significantly. With fewer than 1,000 records, start with a weighted spreadsheet scoring model using historical conversion patterns. Once your dataset grows above 2,000 records, migrate to a no-code ML platform for substantially better accuracy.
How is a propensity model different from lead scoring in HubSpot or Salesforce?
Traditional lead scoring assigns fixed points manually (e.g., +10 for webinar attendance). Propensity modeling uses algorithms to learn which signals actually predict conversions and dynamically weights them. HubSpot Predictive Scoring (Enterprise plan) and Salesforce Einstein bridge the gap by applying ML within the CRM, but they offer less transparency and customization than dedicated platforms.
What if my sales team doesn't trust the model?
Transparency is the antidote. Choose tools that expose feature importance and signal logic. Share the "why" behind scores — e.g., "this account scores 92 because it matches the firmographic profile of your last 15 closed-won deals and visited pricing 4× this week." Start with a pilot team, measure results, and let data build credibility.
How often should I retrain the model?
Most SaaS teams retrain quarterly or semi-annually. Monitor for model drift — if precision or AUC drop by more than 5 percentage points, retrain immediately. Market shifts, product changes, and seasonal patterns all require recalibration.
What's the minimum tech stack needed?
A CRM (HubSpot, Salesforce, or Pipedrive), a no-code ML tool (Akkio, Analyzr, or Graphite Note), and a communication tool for alerts (Slack or email). If budget is zero, start with Google Sheets + CRM data export and a weighted scoring formula using the SUMPRODUCT function.